
Data Availability Layers Arms Race
DA Layers Racing to Save Blockchains from a Scaling Meltdown (Part 3)

tl;dr
The final part of this Data Availability series discusses various data availability (DA) solutions that aim to provide highly available and tamper-proof transaction data storage to support scaling systems like rollups. These include:
Ethereum's base layer which is evolving to offer better DA for rollups via improvements like faster block times, upgrades to consensus and proposals for sharding. However, it faces limitations in latency and storage capacity.
Celestia, an application-specific modular blockchain using advanced cryptographic techniques like erasure coding and data availability sampling to provide fast and secure DA purpose-built for rollups.
EigenDA, a DA layer atop Ethereum utilizing a unique “disperser” model and restaking mechanism to disperse and make data available while leveraging Ethereum’s security. Offers potentially unlimited horizontal scaling.
Avail, using techniques like sharding, parallelization and cryptographic commitments to ensure fast, secure and highly scalable DA natively with features like fraud proofs and cross-shard transactions. Tailored as a DA foundation for rollup networks.
NearDA, offering reliable and ultra-low-cost DA leveraging NEAR’s infrastructure. Boasts specialized components like a Blob Store, Light Client and RPC Clients to enable simplified integration for developers.
The solutions highlight the critical role of DA in making rollup and blockchain scaling possible while showcasing a diversity of architectures from modular blockchains to DA layers atop Ethereum.
We’ve delved deep into each of the DA layers in detail. Right from their technical architecture to understanding the transaction lifecycle within each DA layer.
Introduction
At its core, data availability concerns ensuring that transaction data is accessible for nodes to validate and confirm the state of the blockchain. This is particularly important in decentralized systems, where trust is distributed among various participants. Without proper data availability, blockchains could face security risks, including the potential for fraudulent transactions to go unnoticed.
Rollups are layer 2 scaling solutions that rely on Ethereum’s data availability (block space) to post transaction data and state commitments. The basic rollup workflow involves bundling hundreds of transactions off-chain into a single rollup block and publishing a compact cryptographic proof of the block to layer 1.
The basic workflow of a rollup, involving the bundling of transactions into a single rollup block and then publishing a cryptographic proof to Ethereum, can be broken down into several key steps:
Transaction Aggregation Off-Chain
Users submit transactions to the rollup node.
Rollup node aggregates transactions into a single block, processing them off-chain.
Generating a Cryptographic Proof
Rollup node executes all transactions within the block.
After execution, the node updates the rollup's state to reflect the new balances and data.
The rollup node generates a cryptographic proof, including the new state root and a Merkle proof.
Publishing to Ethereum
The cryptographic proof, along with essential data, is published to Ethereum.
Ethereum nodes verify the cryptographic proof, ensuring the validity of the state transition.
Finalization
Once verified, the block's state update is finalized on Ethereum.
The rollup process repeats with the rollup node beginning to aggregate the next set of transactions.

Participants: The diagram above includes three main participants
User,
Rollup Node, and
Ethereum (representing the Ethereum blockchain).
Flow: The sequence of actions starts with the user submitting transactions to the rollup node, which then aggregates, executes, and updates its state. The rollup node generates a cryptographic proof and publishes it to Ethereum, where it is verified.
Continuation: The process is cyclical, with the rollup node continuously aggregating new transactions after each block is finalized.
This workflow allows rollups to process a high volume of transactions off-chain, reducing the burden on the main Ethereum chain. By only publishing compact cryptographic proofs to Ethereum, rollups maintain security and decentralization while significantly improving scalability and efficiency. This approach is fundamental to Ethereum's scaling strategy and is key to enabling higher transaction throughput and lower fees on the network.
Now, this cryptographic proof contains essential information like the updated state root after transactions are executed and a Merkle proof to verify the inclusion of transactions. However, the actual transaction data is orders of magnitude larger than the proof. The substantial transaction “calldata” needs to be made available somewhere for the validity of the rollup block to be verified. (We have discussed the types of proofs rollups use in part 1 of this series: fraud & validity proofs)
This is where highly available and scalable data from L1 becomes crucially important. The rollups have to post the large transaction “calldata” somewhere that is accessible to all validators. The decentralized layer 1 chain acts as a trustless and tamper-proof store of the “calldata” that validators can retrieve to verify the rollup proof.
Without a scalable data availability layer, rollups cannot support high transaction throughput. If posting calldata becomes a bottleneck, the rollup cannot process more transactions even if the rollup layer can theoretically handle higher throughput. In essence, the scalability of the data availability layer caps the maximum TPS the rollup can achieve.
A scalable data availability layer also aids in decentralization. It allows smaller validators to participate in rollup validation without having to store enormous amounts of data themselves. Availability sampling enables nodes to verify correctness by accessing only a portion of data. This reduces hardware requirements for individual nodes.
The Role of Data Availability in Ethereum
With the advent of Ethereum 2.0 and the increasing use of L2s like rollups, data availability has become a focal point. Rollups, which process transactions off the main Ethereum chain (Layer 1 or L1) and then post the data back to it, rely heavily on robust DA mechanisms. Ensuring that data from these L2 solutions is available and verifiable is critical for maintaining the integrity and security of the entire Ethereum network.
As we spoke about in part two of this series, the DA problem is a serious problem that most of the rollups face. But, before we dive deep into the advanced DA solutions we mentioned in the previous article, it is important that in the context of rollups and the L1 ecosystem, we compare between transaction data (often referred to as "calldata") and cryptographic proofs as it is critical, especially in terms of data management and scalability.
Let's delve into each component in brief:
Transaction Data (Calldata)
Nature of Transaction Data:
Content: Transaction data typically includes all the details necessary to execute and record a transaction on a blockchain. This includes sender and receiver addresses, the amount transferred, smart contract instructions, and any additional data required for the transaction.
Size: The size of this data varies depending on the complexity of the transaction. For simple transactions, it might be small, but for complex ones, especially those involving smart contracts, the size can be significant. As you see from the landscape below, data requirements for each type of scalability solution is different.

Challenges in Handling Transaction Data:
Volume: In a busy blockchain network, the volume of transaction data can be immense, posing a challenge for storage and processing.
Bandwidth: Transmitting large volumes of transaction data requires considerable bandwidth, which can be a limiting factor for network throughput.
Storage: Storing extensive transaction data requires substantial storage capacity, impacting the cost and efficiency of running full nodes.
Decentralization: The need for large storage and bandwidth can lead to centralization, as fewer participants are able to afford the necessary resources to operate full nodes.
Cryptographic Proof
Nature of Cryptographic Proof:
A cryptographic proof, in the context of rollups, typically includes a state root and a Merkle proof. The state root is a single hash that represents the entire state of the ledger after transactions are processed. A Merkle proof, on the other hand, allows for the verification of individual transactions without needing the entire transaction data.
These proofs are significantly smaller than the full transaction data. They are designed to be compact yet sufficient for validators to verify the correctness of transactions.
Advantages in Using Cryptographic Proofs:
Efficiency: Due to their smaller size, cryptographic proofs can be transmitted and processed much more quickly and efficiently compared to the full transaction data.
Scalability: They enable greater scalability of blockchain networks, as they require less bandwidth and storage.
Security: Despite their compact size, cryptographic proofs provide a high level of security, ensuring that the integrity of transactions is maintained.
Transaction Data vs. Cryptographic Proof: The Contrast
The main contrast lies in the size and the corresponding efficiency. Transaction data is large and cumbersome, affecting network performance and scalability. Cryptographic proofs, being much smaller, are more efficient to handle.
This transaction data is the raw material of blockchain operations, representing the actual actions to be recorded. Cryptographic proofs, however, are more about verification and ensuring integrity without the need for handling the full data.
While transaction data is crucial for the actual execution and recording of activities on a blockchain, its size poses significant challenges in terms of data management and network scalability. Cryptographic proofs, on the other hand, provide a solution to these challenges by enabling efficient verification of transactions without the need for the complete data, thereby enhancing scalability, efficiency, and the potential for greater decentralization in blockchain networks.
Now, let’s dive deep into the advanced DA solutions:
Ethereum
Celestia
Avail
EigenDA
NearDA.

Ethereum
Ethereum is one of the leading smart contract L1 platforms that has become the foundation for DeFi and dApps. However, scalability has been a persistent challenge for Ethereum. Its 15 TPS throughput is insufficient for growing ecosystem demands. This led to the rise of layer 2 scaling solutions like rollups that rely on Ethereum's security while bypassing its scalability limits.
But for rollups to work, they need Ethereum to provide highly available and decentralized data storage for transaction calldata. Ethereum is evolving on multiple fronts to meet the data demands of rollups. Let's analyze some of the key developments:
Block Times and Transaction Processing
Ethereum currently produces blocks every ~13 seconds. Reducing block time can improve transaction processing but Ethereum favors security over faster block times. The upcoming Shanghai upgrade will transition Ethereum from proof-of-work to proof-of-stake consensus which improves security guarantees.
Post-Shanghai, Ethereum aims to achieve ~12 second block times providing a good balance between throughput and security. The ~12-15 second block time range is emerging as a sweet spot for many data availability layers.
Finality and Consensus Algorithm
Ethereum uses a hybrid consensus model. Block production uses the GHOST protocol for fast probabilistic finality. The Casper finality gadget provides economic finality by checkpointing blocks every 50 slots (about every 6.25 minutes).
While fast from a proof-of-work perspective, 6.25 minute finality can cause significant delays in settling rollup transactions. But Casper finality will likely keep improving with ongoing research on mechanisms like fork-choice and pivot blocks to provide faster irreversibility.
Approaches to Data Availability
Ethereum is taking a multi-pronged strategy to addressing scalable data availability for rollups - deploying data shards in parallel to execution shards, leveraging L2 systems like Filecoin for data storage, and methods like proposer-builder separation.
EIP-4844 introduces a block size increase via blob transactions and better organization of calldata. This paves the way for massive rollup adoption in the near-term while long-term sharding R&D continues.
Celestia
Celestia is an application-specific data availability blockchain optimized for rollups. Its sharded architecture uses Tendermint consensus to achieve very fast finality and high scalability. Let's analyze Celestia's design:
Block Times and Transaction Processing
Celestia uses a 15-second block time, which provides quick confirmation times for transactions. This enables rollups built on Celestia to process and finalize user transactions much faster than if they relied solely on Ethereum (~15 minutes) for data availability.
Finality and Consensus Algorithm
Celestia achieves finality in a single block using Tendermint consensus, which is a variant of hotstuff BFT consensus. Tendermint provides immediate transaction finality in 1-2 seconds allowing rollups to settle transactions with similar speed and collect fees sooner.
Data Availability Sampling
Celestia will support data availability sampling from genesis which is important to keep nodes lightweight as data throughput increases. Sampling allows validators to verify availability by accessing only a portion of transaction data per block instead of the whole data. This makes Celestia more scalable than chains requiring nodes to download all data.
Celestia is specially designed to be a performant and scalable data availability layer for supporting the needs of rollups. By optimizing the base layer for rollup requirements, Celestia can provide faster finality and higher throughput compared to more generalized blockchains.
Celestia focuses on two key functions:
ordering transactions into blocks and
ensuring their data is available for anyone to download and verify.
This separation of execution from data availability consensus allows Celestia to achieve dynamic scaling, where the network capacity increases with the number of users, and to support a variety of virtual execution environments, giving developers more flexibility and sovereignty over their applications.
Celestia’s architecture is based on the concept of data availability sampling, a technique that allows nodes to probabilistically verify the availability of large data blocks without downloading them in full.
Celestia’s Technical Architecture
Celestia's technical architecture represents a significant evolution in blockchain design, emphasizing modularity and scalability. At its core, Celestia introduces a novel approach to how blockchains handle and distribute data.

Let's delve deeper into the technical specifics:
Modular Design and Data Availability
The foundational principle of Celestia's architecture is its modular design, which decouples the traditional functions of a blockchain into separate layers. This architecture consists of two primary components:
a consensus layer and
a data availability layer.
Unlike conventional blockchains, where consensus, data availability, and execution are tightly integrated, Celestia focuses solely on the first two, leaving execution to be handled independently by other layers or systems. This separation allows for greater specialization and optimization in each layer.
Consensus Layer
Celestia's consensus layer is based on the Tendermint consensus protocol, which is known for its efficiency, fast finality, and robustness against various types of network faults. Tendermint is a Byzantine Fault Tolerant (BFT) protocol that enables a network of validators to agree on the state of the blockchain in a decentralized manner. In Celestia, the primary role of this consensus layer is to order transactions and agree on the data to be included in the blocks. However, it notably diverges from traditional consensus models by not concerning itself with the execution or the validity of the transactions, focusing instead on ensuring their availability.
Data Availability Sampling (DAS)
A key innovation in Celestia's architecture is Data Availability Sampling, which we discussed in detail in part 2 of this series. DAS allows light clients to probabilistically verify that the entire data of a block is available in the network, without needing to download the whole block. This is achieved through cryptographic techniques where the block data is divided into smaller pieces, and only random samples of these pieces are checked by the clients. By confirming the availability of these samples, a client can infer with high confidence that the full block data is available in the network, thus ensuring that the block can be reconstructed if needed.

Erasure Coding
Erasure coding is another critical component of Celestia's data availability mechanism. It involves transforming a piece of data into a longer, redundant form, from which the original data can be recovered even if a portion of the redundant data is lost or unavailable.
In Celestia, blocks are encoded using erasure coding before being disseminated across the network. This means that even if some nodes in the network do not hold the entire block data, the complete block can still be reconstructed from the parts held by the collective network. This redundancy is crucial for maintaining the integrity of the blockchain and for protecting against data withholding attacks, where a malicious actor might try to make a block unavailable.
Network Structure and Operation
In Celestia, validators are responsible for producing blocks and participating in the consensus process. These blocks, once agreed upon, are distributed across the network. Light clients, which do not have the capacity to store the entire blockchain, can still participate meaningfully by performing data availability checks using DAS. This feature significantly enhances the scalability and inclusivity of the network by reducing the hardware requirements for participation.
Execution Layer Independence
Celestia's decoupling of execution from consensus and data availability means that it does not prescribe how transactions should be executed or how state transitions should occur. This opens up a realm of possibilities for innovation in the execution layer, as different systems can use Celestia as a foundation while implementing their unique execution logic. This could range from independent blockchains to Ethereum-based rollups, each benefiting from Celestia's robust data availability and consensus mechanisms while retaining control over their execution environments.
Now that we understand the basics of Celestia’s technical architecture, here is a step-by-step (simplified) visualization of the lifecycle of a transaction on Celestia:
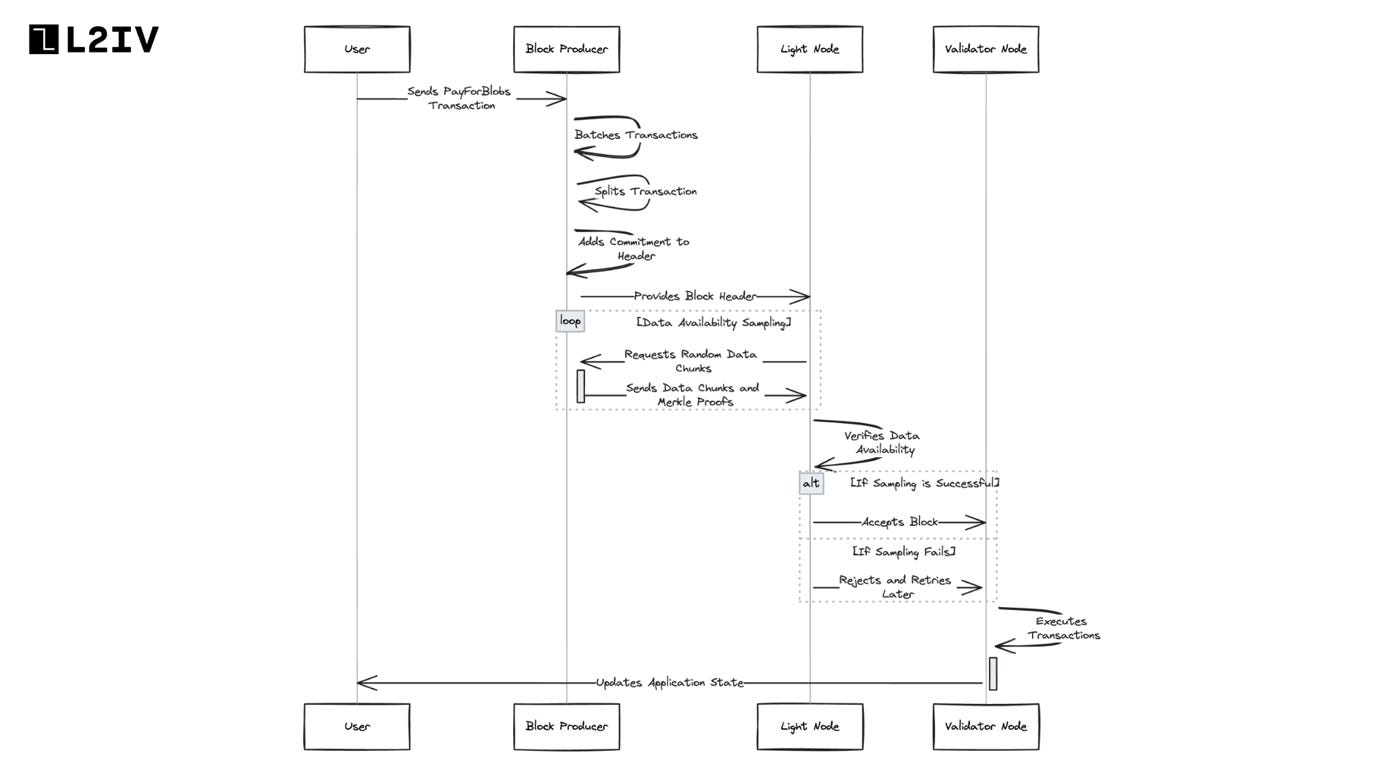
User sends a PayForBlobs transaction to make data available. This contains:
Identity of the Sender: Identifies who is sending the transaction.
Data (Message): The actual data that the user wants to make available.
Data Size: The size of the data to be made available.
Namespace: A unique identifier that categorizes the data, essential for Celestia's namespacing system.
Signature: A cryptographic signature to verify the authenticity of the transaction.
Block producer batches multiple PayForBlobs transactions into a block.
Before proposing the block, the producer splits each transaction into:
Namespaced message - contains actual data (message) and namespace ID
Executable transaction - contains commitment to data but not the actual data
Block data now consists of:
The block data comprises both the namespaced data and executable transactions.
Only the executable transactions are processed by the Celestia state machine once the block is committed.
Block producer adds a commitment to the block header representing the entire block data. This is calculated by:
Splitting transactions and messages into equal sized shares
Arranging shares into a square matrix row-wise
Extending to a larger square matrix using Reed-Solomon encoding
Calculating a commitment for each row and column
The final commitment is the root of a Merkle tree with all row/column commitments as leaves
Light nodes connect to validator nodes to receive block headers and perform Data Availability Sampling (DAS):
Request random data chunks from the extended matrix
Verify they can retrieve the chunks and validate with Merkle proofs
If sampling succeeds, they accept the block as having available data
If sampling fails, light nodes reject the block and retry later to deal with false negatives from network issues.
Parameters like number of samples are tuned to minimize false positives from data withholding.
False Negatives: Sometimes, valid block headers might be rejected due to network issues. In such cases, retrials are necessary.
False Positives: There's a small chance that light nodes might accept a block header even if the data is not available. However, the probability of false positives is sufficiently low, ensuring that block producers have no incentive to withhold data.
Validator nodes execute transactions after block is committed, updating application state.
The lifecycle of a transaction in Celestia-app revolves around ensuring data availability and integrity through a sophisticated process involving user-initiated transactions, block producer processing, data commitment, and rigorous checking by light nodes using data availability sampling. This system ensures that while data is made available and verifiable, the processing burden on nodes is minimized, enhancing scalability and security.
Celestia’s technical architecture, with its modular design, Tendermint-based consensus, innovative use of DAS and erasure coding, and execution layer independence, positions it as a groundbreaking solution in the blockchain space. Its approach addresses some of the most pressing challenges in blockchain technology, namely scalability, data availability, and network participation inclusivity, making it a pivotal development in the evolution of decentralized networks.
EigenLayer
Unlike a base layer blockchain, EigenLayer provides data availability directly at the Ethereum layer 2. It is composed of a set of smart contracts on Ethereum that enables rollups to post transaction data and generate availability proofs on-chain.
Relationship with Ethereum
EigenLayer relies entirely on Ethereum for security and data availability. All data commitments and signatures proving availability are posted to Ethereum via transactions. This provides autonomy to each rollup in handling data but also couples latency, finality and availability to Ethereum's base layer performance.
Consensus and Finality
EigenLayer doesn't have its own consensus algorithm. The rollup operators reach consensus off-chain and submit the outcome as a transaction to Ethereum. Finality is inherited from Ethereum since data commitments are posted on-chain. This currently leads to finality delays of 6-12 minutes for rollups using EigenLayer.
Data Availability Sampling
EigenLayer doesn't explicitly support data availability sampling currently. Nodes likely need to process all data to verify availability proofs. This could limit scaling and decentralization as data throughput increases unless rollups implement custom sampling procedures.
So, what exactly is EigenDA?
Core Concept:
EigenDA is built as a DA service on top of Ethereum, leveraging a restaking mechanism. This approach allows it to integrate closely with the Ethereum ecosystem, enhancing its scalability and data availability capabilities.
Restaking Primitive:
Restaking involves Ethereum validators or stakeholders delegating their stake to node operators who perform validation tasks for EigenDA. This delegation is incentivized through service payments, linking the security of EigenDA to the Ethereum validator set.
Role in the EigenLayer Ecosystem:
EigenDA is set to be a foundational service within the EigenLayer ecosystem, a platform designed to offer various services on top of Ethereum. It aims to provide lower transaction costs, higher throughput, and secure composability for users and applications within this ecosystem.
Scalability and Security:
The throughput and security of EigenDA are designed to scale horizontally with the amount of restaked Ethereum and the number of operators participating in the service.
Let’s explore its architecture in detail:
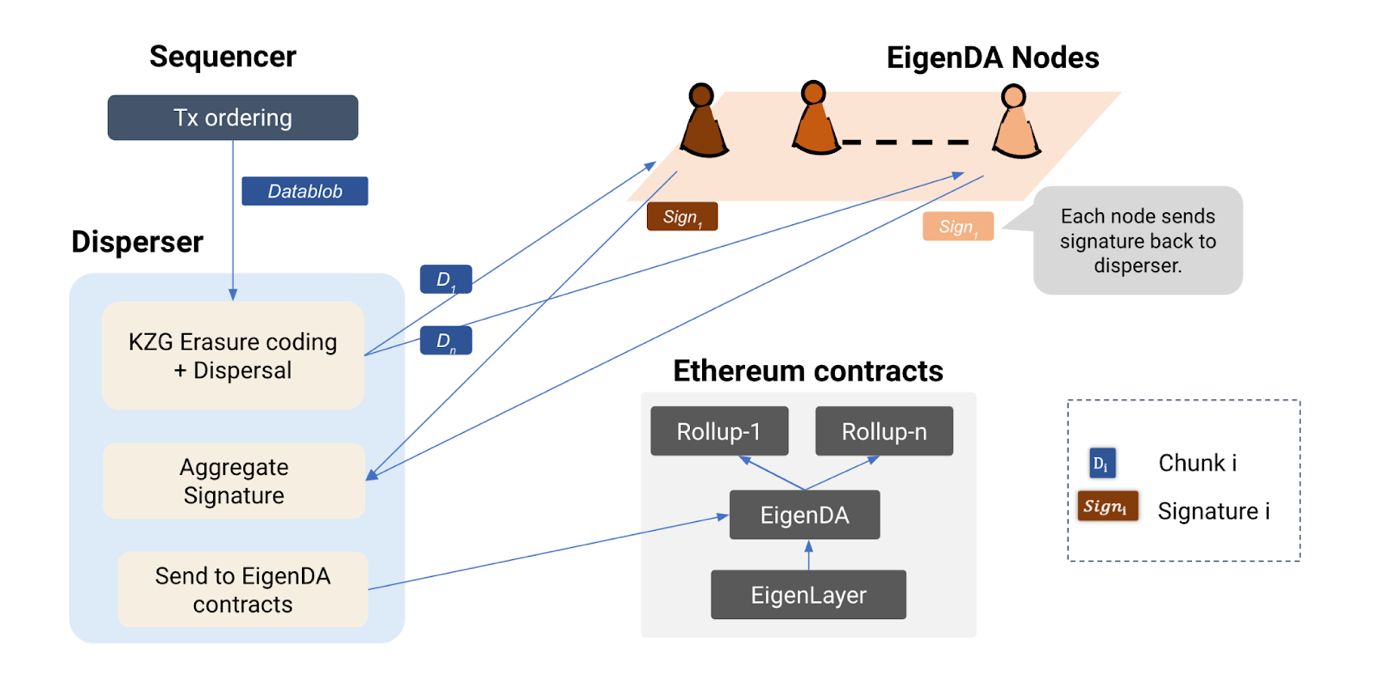
Core Components of EigenDA Architecture
Rollup Sequencer:
The rollup sequencer is responsible for creating blocks containing transactions within a rollup environment. It functions as the initial point of data aggregation.
Once transactions are aggregated into a block, the sequencer initiates the process of making this data available by interacting with the EigenDA network.
Disperser:
The disperser takes the primary role in preparing the data for distribution across the EigenDA network. This involves several key operations:
Data blobs (the aggregated transaction data) are encoded into chunks using erasure coding techniques. This encoding ensures data redundancy and recoverability, enhancing the reliability of the data availability process.
The disperser generates KZG (Kate-Zaverucha-Goldberg) commitments for the encoded data. These commitments serve as cryptographic proofs of the data's integrity and completeness.
Alongside the commitments, the disperser generates multi-reveal proofs. These proofs are used later by the EigenDA nodes to verify the authenticity and completeness of the data chunks they receive.
EigenDA Nodes:
Upon receiving the data chunks and the accompanying KZG commitments and proofs, the EigenDA nodes perform verification to ensure the data's integrity. After successful verification, they store the data chunks.
Post-verification, these nodes generate signatures and return them to the disperser. These signatures aggregate to affirm that the data has been successfully distributed and is available within the EigenDA network.
How does EigenDA Integrate with Rollups and Ethereum?
Rollup Interactions:
Rollups can either operate their disperser or utilize third-party dispersal services. This flexibility allows for cost and efficiency optimizations, particularly in scenarios where third-party services are more efficient or economical.
Rollups maintain the ability to switch to their disperser, ensuring that they are not reliant on a single third-party service, which is crucial for maintaining censorship resistance.
Ethereum Restaking Primitive:
The restaking mechanism allows Ethereum validators to stake their assets (like ETH or staking derivatives) to secure the EigenDA network. This approach extends Ethereum's security model to EigenDA.
Validators are incentivized through service payments for participating in the EigenDA network. However, they also bear additional risks, including potential slashing if they fail to uphold their data availability responsibilities.
Data Availability and Verification
Data Availability Sampling (DAS):
Light Node Participation: Light nodes in the EigenDA network participate in DAS to ensure data availability. They request random data chunks from the extended matrix and validate them using the provided Merkle proofs.
Block Header Validation: Successful sampling and verification of data chunks allow light nodes to validate block headers as having available data.
Handling of False Positives and Negatives:
Network Robustness: The architecture is designed to handle potential false negatives (legitimate data being marked unavailable) due to network issues and minimize the risk of false positives (unavailable data being marked as available).

The above process ensures that data is not only made available but also verifiable by different participants in the network, maintaining the integrity and reliability of the system. The use of a dispersed network of nodes for verification and the aggregation of signatures are key to achieving decentralized and secure data availability in the EigenDA framework.
Economics of EigenDA
Cost Reduction in Data Availability: Rollups currently using Ethereum as their DA layer face high and volatile costs due to limited block space and congestion pricing. EigenDA aims to substantially lower these costs, providing more predictable cost structures for rollups.
Cost Dimensions:
Capital Cost: Staking capital incurs opportunity costs. EigenDA minimizes this by leveraging EigenLayer's shared security model, allowing the same stake to be utilized across multiple applications, thus creating economies of scale.
Operational Cost: Instead of requiring nodes to download and store all data, EigenDA uses erasure coding to split data into smaller chunks, reducing the storage burden on individual nodes and making the system lightweight.
Congestion Cost: EigenDA aims to minimize congestion costs by providing higher throughput and allowing for bandwidth reservation, offering pre-reserved throughput at discounted costs.
Throughput Considerations
Horizontal Scaling: EigenDA is designed for horizontal scaling, meaning that as more operators join the network, the throughput capacity of the network increases. In tests conducted by EigenLayer, EigenDA has demonstrated a throughput of up to 10 MBps, with a roadmap to scale up to 1 GBps.
EigenDA achieves this through:
Decoupling DA and Consensus: It separates data attestation (parallelizable) from data ordering (requires serialization), thereby enhancing throughput and reducing latency.
Use of Erasure Coding: This allows rollups to decompose and encode data into smaller chunks before storing, reducing the amount of data each node must handle.
Direct Unicast for Data Dispersal: Instead of using a peer-to-peer network, EigenDA relies on direct communication for dispersing data, speeding up data commitment times and eliminating the latency associated with gossip protocols.
EigenDA's architecture is characterized by its integration with the Ethereum ecosystem through restaking, a unique disperser model for data encoding and distribution, and a network of EigenDA nodes for verification and storage. This architecture ensures high throughput and decentralized data availability, making it a crucial component for scalability solutions like rollups on Ethereum. It represents a significant advancement in blockchain data availability solutions, leveraging existing Ethereum security mechanisms while providing scalable and efficient services.
Full Disclosure: L2 Iterative Ventures (L2IV) is an existing investor at EigenLayer.
Avail
Avail is fundamentally designed as a base layer blockchain with a specific focus on ensuring data availability. This focus is crucial in the context of scaling blockchain networks and supporting advanced, trust-minimized applications. Avail is tailored to cater to the needs of modern, decentralized applications, including sovereign rollups.

Figure 2: Today, Avail is independent of Polygon
Block Time and Transaction Processing: Avail uses a slightly longer 20 second block time but it enables high TPS in the 1000s range by using sharding techniques like transaction parallelization across shards. The quick block time coupled with cross-shard transactions makes Avail highly optimized for throughput.
Finality and Consensus Algorithm: Avail combines BABE for fast block production with GRANDPA for building consensus across shards. GRANDPA finalizes blocks in the 1-2 second range providing quick finality comparable to Celestia. Such fast finality unlocks the ability for rollups to settle transactions in seconds.
Data Availability Sampling: Avail integrates data availability sampling to keep node requirements low with only partial data needed for availability verification. Erasure coding with validity proofs will be used to efficiently encode data while enabling sampling.
Let’s explore Avail’s technical architecture in detail:
Avail's architecture is structured to optimize the efficiency and effectiveness of each component.

Data Hosting and Ordering Layer (DA Layer)
The DA Layer is responsible for ingesting and ordering transactional data. It serves as the foundational layer of the Avail system.
Unlike traditional blockchain layers, it does not engage in executing transactions. Its primary focus is on storing the data and ensuring its availability.
By focusing solely on data hosting and ordering, the DA Layer addresses the bottleneck issues common in traditional blockchains where every full node is required to execute transactions.
This specialization facilitates scalability and efficiency, as the DA Layer can optimize for data storage and availability without the overhead of transaction execution.
Execution Layer (Exec Layer)
The Exec Layer interfaces with the DA Layer to access ordered transactions.
It processes these transactions and generates essential outputs like checkpoints, assertions, or proofs. These outputs are critical for maintaining the integrity and state of the blockchain.
The generated checkpoints or proofs are committed to the Verification/Dispute Resolution Layer (DR Layer). This layer acts as a security anchor, validating the work done by the Exec Layer.
Verification/Dispute Resolution Layer (DR Layer)
The DR Layer is the adjudicating component of the Avail ecosystem.
It verifies checkpoints or proofs submitted by the Exec Layer, ensuring that only valid state transitions are accepted and integrated into the network.
Network Participants
Full Nodes:
Full Nodes play a crucial role in maintaining the network's integrity. They download and verify the correctness of blocks but do not participate in the consensus process.
Validator Nodes:
Validator Nodes are central to the consensus mechanism in Avail. They are responsible for block generation, transaction inclusion, and maintaining order.
These nodes are incentivized for their participation in the consensus process and are vital for the functioning of the DA Layer.
Light Clients:
Light Clients operate with limited resources and primarily rely on block headers for network participation.
They can request specific transactional data from full nodes, contributing to the network's decentralization and accessibility.
Consensus Mechanism
Nominated Proof-of-Stake (NPoS):
Avail adopts the NPoS consensus model, known for its scalability and energy efficiency.
It utilizes Substrate's BABE/GRANDPA consensus framework, which combines fast block production (BABE) with provable finality (GRANDPA). This blend ensures efficient and secure consensus within the network.
Avail's architecture demonstrates a clear separation of concerns, with each layer focusing on a specific set of functionalities. This modular approach allows for greater scalability and efficiency, as each layer can optimize for its respective tasks without the overhead of unrelated processes.
Its architecture combines erasure coding, KZG polynomial commitments, and Data Availability Sampling (DAS) to ensure robust data availability guarantees.
Let's break down how Avail works:

Transaction Lifecycle in Avail
Transaction Submission
Role of Rollups: As primary consumers of Avail, rollups initiate the transaction process by submitting transactions to the Avail network. Each transaction includes an application ID (appID) that identifies its origin and purpose within the ecosystem.
Data Extension and Erasure Coding
Process: Transactions received by Avail undergo erasure coding, a method that adds redundancy to the original data. This redundancy is crucial for enhancing data reliability and integrity.
Implementation: Data is split into 'n' original chunks and extended to '2n'. This allows for any 'n' out of '2n' chunks to reconstruct the original data. The chunks are arranged in an 'n × m' matrix, which is then extended for added redundancy.
Commitment Creation
KZG Polynomial Commitments: Avail applies these commitments to each block, serving as cryptographic proofs that ensure data integrity.
Coded Merkle Tree (CMT): Blocks are represented using a CMT, with the root included in the block header. This facilitates efficient verification of data by clients and supports constant-sized commitments and logarithmically sized fraud proofs.
Block Propagation
Validators’ Role: Validators receive blocks with commitments, verify the data’s integrity, and reach a consensus on the block. They ensure that only verified and validated data is propagated through the network, often relayed via Avail’s data attestation bridge.
Light Client Network and DAS
Light Client Verification: Following block finalization, light clients employ DAS to verify block data and detect potential data withholding. They download random data samples and check them against the KZG commitments and Merkle proofs, verifying specific data segments without needing the full block.
Full Nodes: They use KZG commitments for reconstructing full data for verification or creating fraud proofs to challenge discrepancies.
Proof Verification
Cell-Level Proofs: Light clients generate these proofs from the data matrix, enabling efficient and independent verification of the blockchain’s state.
Decentralized Verification: This approach ensures a decentralized and secure verification process, critical to the integrity of the Avail ecosystem.
Avail's approach to scalability and data availability centers around the use of advanced cryptographic techniques and a modular network architecture.

Let's delve into its key features: Validity Proofs and Data Availability Sampling (DAS).
Validity Proofs
Use of KZG Commitments:
KZG (Kate-Zaverucha-Goldberg) commitments are a type of cryptographic commitment used in Avail. They are particularly well-suited for Zero Knowledge (ZK) proofs, a cryptographic method that allows one party to prove to another that a statement is true without revealing any information beyond the validity of the statement itself.
KZG commitments are efficient in terms of memory and bandwidth usage. This efficiency is crucial for blockchains, especially those based on ZK proofs, as it reduces the computational load and storage requirements for verifying transactional data.
For ZK-based blockchains, which prioritize privacy and efficiency, Avail’s use of KZG commitments enhances their ability to process transactions securely and swiftly, making Avail a compatible and supportive base layer for these types of blockchains.
Light Client Accessibility and Speed:
Quick Data Access and Sampling: Avail’s light clients are designed to quickly access and sample data from the blockchain. This capability is significant as it allows for swift verification of data availability, a process that is faster compared to systems that rely on fraud proofs.
Advantage Over Fraud-Proof-Based Systems: Fraud-proof-based systems typically require a waiting period to allow for potential challenges to transaction validity. In contrast, Avail’s approach with KZG commitments and efficient light client operations accelerates the verification process, enhancing the overall efficiency of the network.
Data Availability Sampling (DAS)
DAS in Avail allows light clients to verify the availability of data in a trust-minimized manner. This means they can independently confirm that the data they need is available without relying on the full nodes or the central authority of the network. This feature is particularly noteworthy as it distinguishes Avail from networks like Ethereum, which, at least at the current stage, do not equip light clients with DAS. This capability enhances the decentralization and security of the Avail network, as it empowers more participants to actively and independently verify data availability.
Avail’s data-agnostic nature and support for various execution environments further underscore its potential as a foundational layer for DA layers.
NearDA
NEAR's Data Availability (DA) Layer, known as NearDA, offers a transformative solution for Ethereum rollups and developers, providing a cost-effective and reliable platform for data hosting. It's designed to enhance the efficiency and security of blockchain applications while significantly reducing operational costs.

Cost-Effectiveness: One of the standout features of NearDA is its affordability compared to Ethereum's L1. For instance, 100kB of calldata costs approximately $0.0033 on NEAR, whereas the same would cost around $26.22 on Ethereum L1, making NearDA about 8,000 times cheaper.
Reliability and Security: NearDA leverages NEAR's robust L1 infrastructure, which boasts 100% uptime over three years, offering a highly reliable and secure platform for Ethereum rollups and app-chain developers.
Versatility and Adoption: By providing a DA layer to Ethereum rollups, NearDA underscores the versatility of NEAR’s technology and supports a wide range of Web3 projects, contributing to the broader adoption of open web technologies.
Let’s dive deep into NearDA’s technical architecture:
NearDA, designed to provide a cost-effective data availability solution, comprises three primary components that work in tandem to enhance the overall efficiency and reliability of blockchain applications. Each of these components plays a crucial role in the NearDA ecosystem:
1. The Blob Store Contract
The Blob Store Contract serves as a dedicated storage facility within NearDA for arbitrary data blobs. Primarily, these blobs are sequencing data from rollups, but the contract can accommodate various types of data.
NEAR's state storage is economically efficient, making it feasible to store large amounts of data at a relatively low cost.
Data Handling Mechanism:
Non-Storage of Blob Data in Blockchain State: To further reduce storage costs, the Blob Store Contract does not store the actual blob data in the blockchain state. Instead, it leverages the consensus around receipts for data validation.
Receipt Processing and Pruning: When a chunk producer processes a receipt, consensus is reached around that receipt. After the chunk is processed and included in a block, the receipt becomes redundant for consensus purposes and can be pruned after a minimum of three NEAR epochs.
Role of Archival Nodes and Indexers: Following pruning, archival nodes retain the transaction data for longer periods. Indexers also play a vital role in storing and providing access to this data.
The Blob Store Contract utilizes a simplified yet effective method for creating blob commitments. This involves dividing the blob into 256-byte chunks, forming a Merkle tree from these chunks, and using the Merkle root as the commitment. The commitment is then attached to the transaction ID and stored in the contract.
2. Light Client
The Light Client in NearDA is an off-chain, trustless entity equipped with data availability features such as KZG commitments and Reed-Solomon erasure coding.
It provides mechanisms to access and verify transaction and receipt inclusion proofs within a block or chunk. This is particularly useful for validating the submission of dubious blobs or confirming that a blob has been legitimately submitted to NEAR.
Rollup providers can utilize the Light Client to build advanced integration and proving systems, enhancing the security and reliability of their rollups.
3. RPC Client
The RPC Client is the primary interface for submitting data blobs to the NEAR Protocol. It simplifies the interaction with the Blob Store Contract and manages the data submission process.
Variants for Different Languages:
Rust Client (da-rpc): Suitable for applications built using Rust, providing a native interface for interacting with NearDA.
FFI Client (da-rpc-sys): This client facilitates interaction for non-Rust applications by providing a bridge to the Rust client.
Go Client (da-rpc-go): Specifically designed for applications developed in Go, this client interfaces with the FFI client for seamless interaction with NearDA.
The RPC Client acts as a "black box," where developers can input blobs, and the client handles the rest, returning a combination of transaction ID and blob commitment.
Each component within NearDA is meticulously designed to ensure seamless integration, high reliability, and cost-effectiveness, making it an attractive data availability solution for blockchain developers, particularly those working with Ethereum rollups.
Integration in the NearDA Architecture
Data Submission and Storage: Rollups and other applications submit data to NearDA, where it is efficiently stored and managed by the Blob Store Contract.
Verification and Sampling: The Light Client allows for independent verification of data and transaction receipts, enhancing trust and security within the ecosystem.
User Interaction: The RPC Client provides a user-friendly interface for developers to interact with NearDA, streamlining the process of data submission and retrieval.
NearDA emphasizes modularity, making it relatively straightforward for developers to implement their rollups using NearDA, provided they can utilize the da-rpc or da-rpc-go clients.
Compatibility
The NearDA system provides a framework for both Rust and Golang environments to interact with its Data Availability layer, allowing rollups to ensure data availability and integrity while benefiting from cost efficiencies.
Here's how each environment interacts with NearDA:
Rust Environment:

Blob: A structure that contains the data, a namespace identifier, and a commitment (hash).
Namespace: Organizational metadata for Blobs, like version and ID.
FrameRef: A reference to a batch of Blobs, with a transaction ID and commitment.
DaRpc Interface: Defines how to submit and retrieve Blobs.
DaRpcClient: The Rust implementation of DaRpc, interacting with the NearDA layer.
L1: Ethereum's Layer 1, where commitments are posted and verified.
Rust Interaction:
Data is prepared within Blobs and batched in FrameRefs.
The DaRpcClient submits these to the DA layer, ensuring they're stored off-chain on NEAR.
Commitments to the data are posted on Ethereum L1 for security and verification purposes.
This setup allows Rust-based rollups to efficiently manage data storage and maintain integrity.
Golang Environment:

Blob, Namespace, FrameRef: Similar to the Rust environment, these structures organize and reference data.
DaRpc Interface: The same purpose as in Rust, an interface for submitting and retrieving data.
DaRpcSys: A system library that likely calls a Rust-written client, exposed to Go via CFFI.
DaRpcGo: The Go-specific client that provides Go-friendly API functions to interact with the DA layer.
GoRollup: The actual Go implementation of a rollup, utilizing DaRpcGo for DA interactions.
L1: The same role as in Rust, for posting and verifying commitments.
Golang Interaction:
Data is encapsulated in Blobs, organized with Namespace, and referenced by FrameRefs.
Through DaRpcGo, Blobs are submitted to the DA layer, which interfaces with DaRpcSys, and ultimately the DaRpcClient.
Commitments are posted to Ethereum L1, leveraging its security and verifiability.
The architecture caters to Golang's strengths, offering a flexible and scalable solution for rollups in the Go ecosystem.
Now, let's break down how the transaction cycle of NearDA works:

1. Transaction Creation
A user initiates a transaction on a rollup network, which results in the creation of a data blob.
The rollup processes this transaction and prepares the data blob, which encapsulates the transaction data.
2. Data Blob Submission
The rollup interacts with the Blob Store Contract on NearDA using the RPC Client tailored to its programming language (e.g., Rust, Go).
The rollup submits the data blob to NearDA, where it's managed without storing the actual data in the blockchain state for cost efficiency.
3. Data Availability and Consensus
Upon submission, a receipt is created by the network, signifying that the transaction has been processed.
NEAR validators reach a consensus on the receipt, which is then included in a block.
After a certain time, the receipt can be pruned. Archival nodes and indexers take over the responsibility of maintaining the transaction data.
4. Commitment Creation
The data blob is chunked into pieces, from which a Merkle tree is created.
The root of the Merkle tree becomes the commitment to the blob, ensuring the integrity of the data.
5. Light Client Verification
The Light Client, equipped with data availability features, fetches inclusion proofs for the transaction and receipt.
It uses these proofs to validate the submission of the data blob to NearDA, ensuring that the data is indeed available and correctly stored.
6. L1 Interaction
The commitment to the data blob, now part of the transaction ID, is posted on the Ethereum Layer 1 blockchain.
This step secures the proof of data availability and verifiability, anchoring the NearDA's commitments to the more secure Ethereum network.
7. Ongoing Availability
As the rollup continues operation, it may need to access or reference the data stored within NearDA.
The Light Client may be used to verify the data or to provide proofs for any disputes or audits that arise, ensuring ongoing data availability and integrity.
8. Archival and Pruning
Archival nodes ensure long-term storage of the data blobs, while indexers allow for retrieval when needed.
Over time, data that is not needed may be pruned according to NearDA’s data retention policies, completing the lifecycle of a transaction.
Note: The above is a step-by-step understanding of NearDA’s working based on our internal research. It is still early to determine Near’s footprint.
Conclusion
The growing demands on L1 scalability have made data availability a pivotal issue in blockchain architecture designs. As this DA series explores, scaling systems like rollups rely heavily on access to transaction data across a decentralized network of participants to function securely. Without robust, tamper-proof data availability, they face limitations in throughput, latency, costs, and vulnerability risks.
Advanced cryptographic solutions are emerging to address these data availability bottlenecks. Celestia, Avail, and NearDA represent purpose-built DA layers tailored to optimize performance, costs and security for rollups. EigenDA offers a DA service atop Ethereum that hopes to match dedicated DA chains on metrics while benefiting from Ethereum's security. And Ethereum itself continues to evolve its base layer to better support rollups in data needs.
Each solution comes with its unique set of trade-offs across metrics like costs, throughput, security models, and ease of adoption.

Celestia and Avail promise an application-specific focus on DA and optimizations like faster finality unsuitable for generalized smart contract execution.
Whereas EigenDA and NearDA aim to provide more versatile DA across use cases while being constrained by Ethereum's limitations in some aspects.
For developers building rollup and advanced scaling systems, assessing their specific DA requirements and finding the most fitting solution will be key. For users, these platforms collectively showcase how data availability is being transformed into a scalability engine that will likely change how we interact with blockchains.
As we wrap up this three-part series, the innovations underscore how data structures and availability in the decentralized tech stack are now equally as important as security and decentralization for delivering performance, cost efficiency and reliability.
Specialization, modular architecture, and horizontal scaling allow these platforms to push the boundaries on DA while maintaining decentralization for users. With demand growing, data availability layers seem poised to drive the next bull run in blockchain infrastructure.
Find L2IV at l2iterative.com and on Twitter @l2iterative
Author: Arhat Bhagwatkar, Research Analyst, L2IV (@0xArhat)
References:
Data Availability: The Overlooked Pillar of Scalability (Part 1)
Rollups vs. Data Availability Problems: Battling for Auditability (Part 2)
Extra read: A data availability blockchain with sub-linear full block validation
Disclaimer: This content is provided for informational purposes only and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisors as to those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services.