
Rollups vs. Data Availability Problems
Battling for Auditability (Part 2)

tl;dr
Part 2 of the DA series explores the data availability problem plaguing blockchain networks and layer 2 rollup solutions.
On Ethereum, data is inherently available on-chain. But rollups process transactions off-chain, posing an availability problem - sequencers who aggregate transactions lack incentives to keep data available long-term.
This prevents users from verifying state, submitting fraud proofs, or withdrawing funds if sequencers limit data access over time. Examples show how withholding data in both optimistic and ZK rollups obscures the true state despite valid proofs.
Initial rollup designs post all data to Ethereum as calldata for availability. But calldata is expensive and capacity-limited, constraining rollup scaling. Ethereum's lack of pruning also bloats costs of keeping rollup data available on-chain indefinitely.
To enable genuine decentralization and permissionlessness, rollups need solutions providing efficient,
verifiable off-chain data availability without excessive on-chain costs.
Promising techniques include data availability schemes, and data availability sampling.
Robust data availability is pivotal for rollups to deliver their promised scalability, auditability, and user sovereignty. Ongoing research on availability schemes aims to prevent sequencer centralization risks and unlock the full capabilities of layer 2.
Last week, we dove deep into detail about what Data Availability is in this 3-part series on Data Availability.
We explored why data availability matters by diving deep into:
Transaction lifecycles in PoW and PoS - Shows where availability bottlenecks emerge during validation and consensus stages.
Comparing Ethereum and rollups - Ethereum provides inherent on-chain availability. Rollups face the "data availability problem" of incentivizing sequencers.
Rollup cryptography - Fraud and validity proofs fundamentally rely on accessible data to function securely.
Users require availability to verify balances, submit transactions, and audit independently. For rollups, availability enables open participation, state derivation, and security. It makes scalability about data schemes, not just throughput.
In this part 2, we explore the problems existing around data availability.
Introduction:
Layer 1 blockchains strive to achieve the challenging "scalability trilemma" - providing decentralization, security, and scalability simultaneously. This remains difficult with the limits of current layer 1 chains like Ethereum, which offers robust decentralization at the cost of meager 15 transactions per second throughput. Layer 2 rollups have emerged as a leading technique to improve blockchain scalability by processing transactions off the main chain while inheriting its security guarantees. Rollups handle execution outside layer 1 but post succinct proofs periodically to leverage the base chain's decentralization and security for validation.
The Data Availability (DA) problem stands out as a pivotal concern in blockchain networks, especially when we consider the evolving landscape of scalability solutions like rollups. This issue fundamentally revolves around ensuring that everyone in the network has access to all the data in a newly added block. Why does this matter so much? If data isn't fully available, it opens the door to potential risks, including the hidden malicious transactions by the block producer, potentially undermining the system's security and integrity.
Delving into the Essence of the Data Availability Problem
At its heart, the Data Availability problem poses a critical question for blockchain networks: "How can we be certain that all the data in a newly proposed block is indeed available to every participant?" The inability to guarantee this availability can seriously jeopardize any blockchain's reliability.
Hence, the data availability problem refers to the challenge of ensuring transaction data remains reliably accessible to all network participants in layer 2 solutions like rollups.
As this DA series focuses only on Ethereum, we can be certain that in Ethereum, data availability is inherent - full transaction data is stored directly on-chain and replicated across all nodes. But rollups process transactions off-chain, only posting compressed proofs to L1. This saves costs but jeopardizes availability.
Rollups rely on a sequencer to aggregate transactions off-chain and produce succinct proofs for submission to Ethereum. However, the sequencer has no incentive to make the full data available to users long term. They are focused on maximizing throughput and minimizing costs.
Yet the raw transaction data must still be accessible in rollups for users to derive current state balances, submit fraud proofs if needed, and withdraw funds. If sequencers limit access over time, it hinders auditability and disputes.
Hence, rollups face a dilemma - transaction data cannot be fully stored on-chain like Ethereum due to fees and bloat. But off-chain availability depends on incentivizing sequencers to retain and provide data access.
Rollups and Their Data Availability Challenges
In the realm of rollups, which are advanced Layer 2 solutions designed to boost blockchain scalability, this problem becomes even more pronounced.
Optimistic rollups require the raw transaction data to be posted on-chain so nodes can monitor activity and submit fraud proofs if they detect invalid state transitions. Without comprehensive data availability, misconduct or errors could go unnoticed in the rollup since nodes cannot actively check for fraud without the underlying data. The full transaction details must be accessible on-chain in order for the security model of fraud proofs and optimism to function effectively.
In contrast, ZK rollups do not require on-chain transaction data, thanks to validity proofs. However, the raw data must still be made available off-chain for users to derive the actual state of their accounts and balances. If transaction data was unavailable to users in a ZK rollup, it could lead to situations where funds are provably and verifiably sent to a user's account in the validity proof, but that user has no way to look up or determine their updated account balance and current holdings, since they do not have access to the underlying data. Even with validity proofs ensuring correctness, data availability remains essential for deriving rollup state.
Let's break it down with a couple of examples:
1. ZK Rollup Example:
The ZK rollup sequencer collects and batches the following trades:
Ryan sends 3 ETH to Arhat
Charlie sends 5 ETH to Dan
Eve sends 2 ETH to Fabian
The sequencer generates a valid zero-knowledge proof attesting to the correctness of these trades and posts it on Ethereum. However, the sequencer does not make the actual trade details available on-chain or off-chain. Without the underlying data, users have no way to verify their balances or the trades executed, even though the proof is valid. The sequencer can obscure the true rollup state despite posting valid proofs by withholding the data.
In this ZK Rollup scenario, the sequencer plays a crucial role:
Protocol's Function: The sequencer collects and processes a series of trades. It then generates a zero-knowledge proof that attests to the correctness of these trades and posts this proof on the Ethereum main chain.
Data Availability Issue: Despite the proof's validity, the sequencer does not make the actual trade details available either on-chain or off-chain. This omission creates a significant gap in transparency and verifiability.
User Implications: Users like Ryan, Charlie, Dan, Eve, and Fabian are left without any means to verify their new balances or the execution of the trades. The valid zero-knowledge proof ensures the trades' validity in principle but fails to reveal any specific details about them.
Potential for Misuse: By withholding the full trade data, the sequencer can obscure the true state of the rollup. This creates a situation where valid proofs are posted, yet the lack of data availability prevents users from independently verifying their transactions and balances.
2. Optimistic Rollup Example:
The optimistic rollup sequencer batches the following off-chain trades:
Ryan sends 3 ETH to Arhat
Charlie sends 5 ETH to Dan
Eve sends 2 ETH to Fabian
The sequencer posts a transaction to Ethereum that contains:
A hash commitment representing the bundled trades
Any signatures required to post the batch
During the challenge period, the sequencer makes all details available except for Ryan's trade. Without the data, users cannot challenge the invalid omission. When the challenge period expires, the sequencer performs an invalid 3 ETH withdrawal from Ryan's account using his signature. Ryan cannot dispute it without the omitted data.
The Optimistic Rollup example highlights a different aspect of the data availability problem:
Role of the Sequencer: The sequencer batches off-chain trades and posts a hash commitment of this bundle to Ethereum. This action is meant to represent the new state of the rollup.
Challenge Period Dynamics: During the challenge period, the sequencer makes most trade details available except for critical information regarding Ryan's trade. This selective disclosure hinders the ability of users to effectively challenge the state transition.
Exploiting the Challenge System: After the challenge period expires without any successful challenge, the sequencer performs an invalid withdrawal from Ryan’s account, using his signature. The lack of complete data availability makes it impossible for Ryan or other users to dispute this action.
System Integrity at Stake: Such actions by the sequencer can erode trust in the system. Users are unable to validate or challenge transactions, leading to potential misuse and exploitation of the rollup's mechanics.
These examples illustrate the data availability concerns in both rollup types - valid proofs or commitments do not ensure users can actually access the underlying data required to derive the true state and audit accounts. Availability schemes are essential to prevent operator censorship, omissions, or errors from going undetected. It also highlights how valid cryptographic commitments alone are insufficient to guarantee decentralized security. Behind the proofs, users require data accessibility to audit outcomes themselves.
We often focus on the elegant cryptography underpinning systems like rollups. But the raw data anchoring those proofs to reality is equally important. Advanced cryptography is meaningless if manipulated or clandestine data corrupts the output.
Data availability cuts to the core of what it means for a system to be "trustless". Trustlessness requires users to have access to the same information as operators to independently derive outcomes. Assurances without that auditability become "trust-based".
In addressing the challenges posed by the Data Availability (DA) problem, both Optimistic Rollups and Zero-Knowledge Rollups initially adopt a strategy that involves operators submitting comprehensive transaction details onto the Ethereum blockchain as ‘calldata’. This method effectively circumvents the DA issue in the short term by ensuring that all necessary transaction data is accessible on the Ethereum chain.
Note: We discussed the topic of calldata in the upcoming EIP-4844 (proto-danksharding) update in our previous articles.
However, this approach encounters scalability limits as the volume of transactions processed within the rollups increases. The larger the number of transactions, the greater the volume of data that needs to be submitted as calldata. This increment in data submission directly impacts the Ethereum network's capacity, ultimately posing a potential bottleneck to the scalability that rollups are designed to achieve. The growing amount of data can lead to increased transaction fees and network congestion, counteracting the scalability advantages of rollups.
Complicating the situation further is the nature of data unavailability in these systems. It's characterized as a non-uniquely attributable fault, meaning that it's challenging for participants to conclusively prove to the rest of the network that specific data is missing.
For example, consider a scenario where Ryan announces that a block submitted by Arhat is lacking certain data. However, if Charlie directly approaches Arhat for this information, and he provides it, the claim of data unavailability becomes disputable. This scenario highlights a critical issue: even if data is missing or inaccessible to some participants, it may not be uniformly the case for all, making it difficult to universally verify claims of data omission.
What Role Roes "calldata" Play in Data Availability?
Functionality: Calldata in Ethereum serves as a carrier of information for smart contract function calls. It contains all the necessary data for a contract to execute a specific function, including the function's parameters.
Propagation and Storage: As part of the Ethereum transaction process, calldata gets propagated across the network. It becomes a permanent part of the blockchain record, stored by all nodes. This universality and immutability of calldata make it a reliable source for data availability.
Use Cases: Calldata's use extends beyond simple contract executions. It can be employed for diverse applications such as broadcasting updates from decentralized applications (dApps). By encoding data into calldata, developers can ensure its availability and persistence on the Ethereum blockchain.
As part of the transaction propagation process, calldata gets replicated and permanently stored in the transaction record by all Ethereum nodes. This makes calldata a convenient source of inherent on-chain data availability.
For example, a dApp could deploy a contract with a simple "updateData" function and call it whenever they need to broadcast data, encoding the data in the calldata. This ensures the data gets replicated across all nodes and becomes available on-chain for anyone to access.
However, this calldata approach has downsides when used for data availability by rollups. As rollup transaction volume increases, the fees of posting all data via calldata becomes prohibitively expensive. Ethereum's lack of pruning also means old rollup data must stay available via calldata indefinitely, further bloating costs.
Relying heavily on calldata for data availability poses major scalability issues for rollups due to two key limitations:
1. High Costs: Posting data via calldata transactions incurs the standard Ethereum transaction fees based on gas costs.
Each byte of calldata costs 16 gas. This means the cost of data availability scales linearly with the amount of data. For rollups processing thousands of transactions in a batch, the cumulative calldata costs become prohibitively expensive.
At a certain transaction volume, the fees alone would overwhelm Ethereum's capacity limits. This cost overhead counters the throughput gains rollups are designed to provide.
For example, a rollup batch with 50 KB of calldata would incur ~800,000 gas in calldata costs at 16 gas/byte. At 100 gwei gas prices, that's 0.08 ETH or $100+ just for calldata availability per batch.
Clearly, relying solely on calldata for rollup data availability does not scale well cost-wise as transaction count rises. It burdens Ethereum with excessive fees while hampering rollup throughput.
2. Limited Block Space: Beyond the linear cost scaling, calldata also faces hard capacity limits.
Ethereum blocks have restricted space, currently around 10-15 KB per block cumulative.
This finite capacity constrains how much rollup data can be posted via calldata. Ethereum's maximum throughput caps the data availability bandwidth rollups can achieve relying on calldata alone.
While the exact limits are adjustable with gas limit changes, at some point calldata space will be overwhelmed as rollups scale transaction volume. Availability solutions that do not burden Ethereum's base layer are necessary.
For these reasons, in the long term rollups need more efficient off-chain data availability schemes that don't overload Ethereum with excessive data replication. Cryptographic commitments and erasure coding are among the solutions being explored to address these needs.

We can infer from the above table that
For ZK rollups, calldata allows availability of proofs but incurs substantial costs that threaten scaling. Off-chain innovations are needed to supplement calldata.
In optimistic rollups, calldata provides transaction details essential for fraud proofs during challenge periods. But permanence exacerbates network load issues.
The key to rollup decentralization is
scalable off-chain availability that minimizes reliance on calldata block space.
Another solution is the upcoming EIP-4844 update, which we have covered here in detail: The road to danksharding.
How Data Availability Affects Ethereum Today
At its core, blockchains rely on decentralization and distributed consensus to provide security and immutability guarantees. However, deficiencies in data availability can undermine these foundations, particularly impacting light clients that cannot perform full transaction validation themselves. In a typical blockchain, blocks consist of two key components:
Block Header: The block header is a compact segment containing crucial metadata and digests related to the transactions in the block. It's essentially the block's identification, summarizing its contents and linking it to the rest of the blockchain.
Block Body: This larger part of the block houses all the transactional data. It's what makes up most of the block's size and contains detailed information on all transactions processed in that block.
Now, Full Nodes are the backbone of conventional blockchain protocols. They download and synchronize the entire block, verifying all the state transitions. Full nodes expend significant resources to validate transactions and store the blocks. Their key advantage lies in their autonomy – they are not compelled to accept any invalid transaction due to their comprehensive verification process.
Full nodes contribute significantly to data availability as they hold a complete record of the blockchain. This comprehensive data set allows them to provide accurate and complete information about the state of the network to other participants.
They are essential in validating and relaying transactions and blocks, ensuring the integrity and consistency of the blockchain.
On the other end of the spectrum are light clients, which operate with limited resources. These nodes are primarily concerned with ascertaining the current state of the blockchain and confirming the inclusion of relevant transactions. They don't verify every transaction but rely on other mechanisms to stay informed and secure.
Light clients contribute to data availability by providing a more resource-efficient way to participate in the network. They allow users with limited storage and bandwidth to verify transactions and interact with the blockchain.
While they depend on full nodes for complete transaction data, their ability to verify the integrity of the data through block headers helps maintain trust in the network's data.
As we discussed earlier, Fraud proofs are succinct pieces of evidence that a particular block contains an invalid transaction. Any full node can generate these proofs, offering light clients a way to verify the validity of transactions without needing to trust any single full node. However, the system falters when a block producer withholds data. Full nodes would reject such a block, recognizing it as incomplete. Light clients equipped only with the block header might not detect the missing data. Moreover, without the full data, full nodes are incapable of producing fraud proofs.
DA Problems in the Context of Full Nodes and Light Clients
Challenge in Light Clients Verification: If there is a data withholding attack, or data is not readily available, light clients may not have enough information to ascertain the validity of the blockchain state or specific transactions.
Fraud Proofs and Data Availability: With Optimistic Rollups, the generation of fraud proofs (to dispute incorrect state transitions) heavily relies on data availability. Full nodes need access to complete data to produce these proofs, which light clients depend on for security.
We only discussed the problems around light clients and full nodes, but below, we have mentioned several other challenges in DA.

What Are The Solutions To The DA Problem?
Below, we have outlined a comprehensive view of the solutions for data availability problems, along with the different approaches taken to ensure data is accessible and verifiable in a secure and scalable manner. Each method addresses specific challenges associated with data availability in blockchain networks, particularly in Ethereum and similar architectures.

However, we will only be discussing the subcategories of off-chain Data Availability: Data Availability Schemes and Data Availability Sampling in this article and dive further deep into the Data Availability Layers entirely in Part 3 of this series. By off-chain here, we mean “off-the main chain”, i.e., Ethereum.
Data Availability Schemes
Data availability schemes refer to a category of protocols and cryptographic methods that allow layer 2 networks like rollups to prove and validate the availability of transaction data without relying on a separate data availability layer.
They aim to provide efficient and scalable data availability while minimizing the burden on the underlying layer 1 blockchain. Some key examples of data availability scheme approaches include:
1. Erasure Coding:
Mechanism: Involves expanding the original dataset by adding redundant parity data, which is then fragmented. The key advantage is that the original data can be reconstructed from a subset of these fragments.
Verification: Nodes in the network can randomly sample these fragments to verify the overall availability of data, without needing the entire dataset.
Benefits: Enhances data redundancy and fault tolerance, allowing for efficient proof of availability.
2. Polynomial Commitments (KZG Commitments)
Data Encoding: This method encodes transaction data into a polynomial function. The data is then committed using cryptographic hashing techniques, creating a compact representation (commitment) of the entire dataset.
Verification Process: Nodes can verify the availability of specific data by evaluating parts of this polynomial. KZG commitments use bilinear pairings for this purpose, allowing for efficient and secure verification.
Advantages: Offers a scalable way to handle large datasets and provide proofs of data availability with reduced computational overhead.
3. Interactive Oracle Proofs
Dynamic Proofs: These involve block producers providing data availability proofs in response to random challenges. The process is interactive, with verifier smart contracts issuing challenges and evaluating responses.
Incentivization: Correct responses are incentivized through a penalty system, ensuring that block producers are motivated to provide accurate availability proofs.
Characteristics: The proofs are generated dynamically, adding flexibility to the verification process.
4. zk-SNARKs
Non-Interactive Proofs: zk-SNARKs (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge) enable the creation of proofs that can validate statements about data availability without revealing the data itself.
Complexities: While powerful, they require a trusted setup and can be computationally intensive in terms of proof generation.
Use Case: Suitable for scenarios where privacy is paramount, and the trade-offs in terms of setup and computation are justified.
Role in Layer 2 Scalability: By integrating these data availability schemes with fraud and validity proofs, Layer 2 solutions like rollups can achieve significant scalability improvements. They manage to maintain security and data integrity without overwhelming the Layer 1 blockchain's capacity.
Data Availability Sampling (DAS)
DAS refers to a method for efficiently verifying that full data is available without having to retrieve the entire dataset. It works by randomly sampling fragments from an erasure-encoded dataset.
Core Mechanism of Data Availability Sampling
The process begins by expanding the original dataset using erasure coding, which not only adds redundancy but also enables the reconstruction of the entire dataset from a subset of the data. The expanded dataset is then fragmented and distributed across various nodes. Light clients or other participating nodes perform random sampling by requesting specific fragments from this distributed dataset.
Let’s explore this with an example:
Consider an L1 where a 1 GB block of data needs to be verified for availability.
Using erasure coding, this 1 GB block is encoded into a 2 GB dataset. The encoding process adds redundancy, allowing the original data to be reconstructed from parts of this expanded dataset.
Fragmentation and Distribution:
The 2 GB dataset is then split into four fragments, each of size 0.5 GB.
These fragments are distributed across different nodes in the network, ensuring that no single node holds the entire dataset.
Sampling Process by a Light Client:
A light client, which does not download the entire blockchain, participates in verifying data availability.
The light client randomly requests a few of these 0.5 GB fragments from different nodes across the network.
If the nodes successfully provide these fragments, the light client gains confidence that the full 1 GB block is likely available somewhere in the network. The more fragments it successfully retrieves, the more certain it becomes of the block's availability. By successfully retrieving randomly selected fragments, a node can statistically infer the availability of the entire dataset. The probability that the complete data set is available increases with each successfully retrieved sample, allowing for a high degree of confidence without needing to access the full data.
Why This Approach Is Effective:
This method is advantageous because it allows the light client to verify the block's availability without the need to download and store the entire 2 GB. This process significantly reduces the data burden on the light client.
It's an efficient way for nodes, especially those with limited capacity, to participate in maintaining the network's integrity and ensuring that data is not being withheld.
The key requirements are:
Fragments are distributed pseudo-randomly across nodes using erasure coding. This prevents targeted unavailability.
The sampling protocol and source of randomness must be unpredictable to prevent manipulation. Verifiable random functions are often used.
There must be penalties if nodes cannot provide the fragment they are challenged for, to economically compel availability.
As long as challenges are robust and probabilities managed carefully, data availability sampling allows light clients to efficiently check availability with minimal data transfer. The overhead is proportional to the amount sampled rather than the full dataset size. This permits verification of large blockchain datasets without excessive resource costs for light clients.
Requirements for Effective Data Availability Sampling
Pseudo-Random Distribution of Fragments: The fragments must be distributed in a pseudo-random manner across the network, ensuring that no single node or group of nodes can predict which fragments they will be responsible for. This distribution strategy prevents intentional data withholding or targeted unavailability.
Unpredictable Sampling Protocol: The protocol for selecting which fragments to sample must be unpredictable and resistant to manipulation. Techniques like verifiable random functions (VRFs) are often used to achieve this unpredictability. Ensuring randomness in the sampling process is crucial for maintaining the integrity and reliability of the DAS method.
Economic Incentives and Penalties: Nodes must have economic incentives to store and provide data fragments accurately. Penalties for failing to provide requested fragments are essential to compel nodes to maintain data availability. These economic mechanisms ensure that nodes are motivated to participate honestly in the data availability process.
Now that we have explored on-chain DA, and subsets of off-chain DA, here’s a comparative guide on DA strategies:
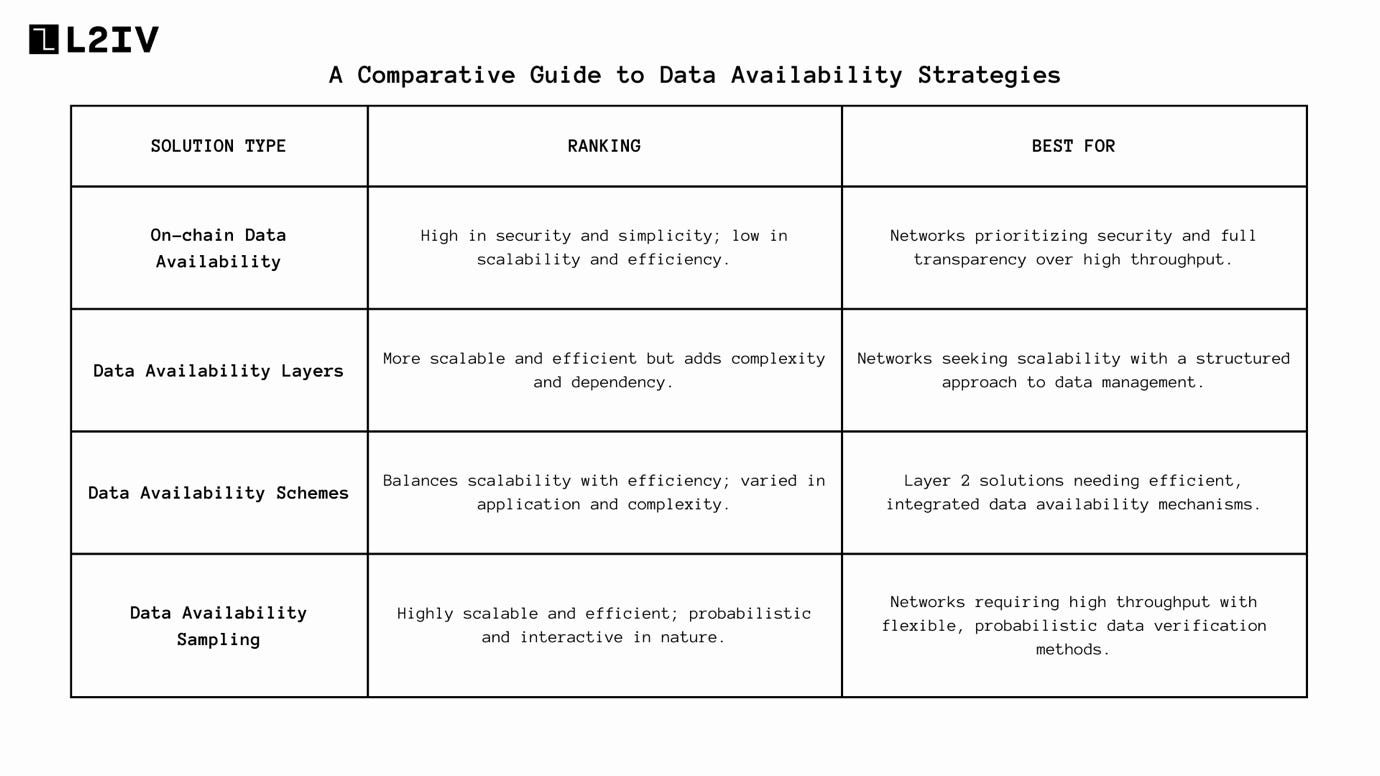
Wrapping It Up
The data availability problem is a significant barrier to ensuring the security and efficacy of blockchain scalability solutions like rollups.
Mandating the submission of all transaction details to the main chain is a stopgap measure, but it doesn't scale well in the long run. Plus, the challenge is compounded by the difficulty in universally proving the absence of data due to its non-attributable fault nature.
Tackling this issue is vital for preserving the integrity, security, and desired scalability of blockchain networks.
In the final part of this series, we will explore in detail the different data availability layers—Celestia, Avail, EigenDA, and NearDA.
Find L2IV at l2iterative.com and on Twitter @l2iterative
Author: Arhat Bhagwatkar, Research Analyst, L2IV (@0xArhat)
References:
Data Availability: The Overlooked Pillar of Scalability (Part 1)
The Road to Danksharding: Everything You Need to Know About EIP-4844 in Bite-Sized Blobs
Disclaimer: This content is provided for informational purposes only and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisors as to those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services.