
Domain-specific languages for Bitcoin
Finding Solidity for Bitcoin

Recently, we released our implementation of a Plonk verifier in Bitcoin script, with STARK and OP_CAT. The Plonk verifier has been tested on Bitcoin Signet and also, Fractal Mainnet. One important difference between this Plonk verifier and the Fibonacci verifier that we released on July and on August is that, instead of writing the Bitcoin script opcode-by-opcode in a manual manner, the code for the Plonk verifier is mostly written in an embedded domain-specific language (eDSL) that is built on top of Rust.
In this article we want to talk about DSL for Bitcoin, and how it may help onboard developers into the Bitcoin ecosystem, similar to what Solidity has done to Ethereum. We, however, should admit that our eDSL is far from being a “Solidity” for Bitcoin since it is a very early attempt and there are going to be more DSLs coming out (and we think another DSL, sCrypt, is closer to being the Solidity of Bitcoin, as mentioned below), but we also believe that with the availability of DSLs including ours, developers no longer need to program opcode-by-opcode, so the developer ecosystem in Bitcoin has fundamentally changed and, we are not going back.
DSL and Bitcoin
Domain-specific languages are programming languages that are designed for certain applications, and the goal is to make programming easier and safer.
Solidity can be considered as a very successful example, especially with OpenZeppelin’s smart contract libraries that standardize a number of common components.
Older examples of DSL that still prevails include Verilog and VHDL for hardware designs that save, of course, hardware engineers from drawing billions of transistors by hand.
Epic Games has a DSL, called Verse, for writing games on Unreal Engine that has been used in building their world-class game, Fortnite.
A domain-specific language can be entirely a new creation, but the common practice is to base this new language over an existing language, such that it is easier to develop and maintain, and it is easier for new developers to learn. A special case is something called “embedded domain-specific language” (eDSL), which is a domain-specific language that is fully implemented over an existing language, as a library, so we do not need to implement a parser and an entire new development toolchain.
Our eDSL is implemented over Rust. Developers who are familiar with Rust should require close to no time to get used to this eDSL. The main goal for our eDSL is to reduce the learning curve as well as to improve “ergonomics”—just in general the developer experience.
Bitcoin is sort of new to DSL. Previously, we only had DSLs for Bitcoin that targeted simple spending policies (which were also the most common use cases of Bitcoin scripts at the time). One is called `bitcoin-dsl`, which is focusing on providing a human-friendly interface to describe the multisignature and timelock requirements for a transaction to be spent. This is already powerful enough to, for example, implement the Lightning Protocol and the Ark protocol using a few lines of code, and has received a lot of appreciation.
For example, with `bitcoin-dsl`, if I want to specify a classical timelock policy (that is used in Ark), in that Alice can redeem the money now if the ARK Service Provider (ASP) agrees, or, Alice can unilaterally redeem the money without the support from ASP if it reaches the timeout period. Traditionally, people need to write this in Bitcoin script almost manually, and it can be very error-prone. Now, one can just define this policy in a human language, as shown below.

Another example is Minsc, built on top of Miniscript, which follows a similar purpose and functionality. For example, if we want to implement a policy saying that the transaction requires a 3-out-of-3 multisig, but after 90 days, it would be relaxed into 2-out-of-3, Miniscript allows one to write the spending policy as follows:
thresh(3,pk(key_1),pk(key_2),pk(key_3),older(12960))
“thresh” here means that among the four things, at least three of them need to happen. These four things are (1) signed by key_1, (2) signed by key_2, (3) signed by key_3, or (4) the UTXO has existed for more than 12960 blocks (roughly but not exactly, 90 days). The Miniscript compiler is able to convert this into a few lines of script, as follows.

A limitation about these DSLs is that their scope has been limited into spending policies and their combinations, but not more complicated Bitcoin script, such as “computation” for, like, Bitcoin STARK verifier.
A more powerful candidate is sCrypt, which is a TypeScript-based smart contract DSL that was originally designed for Bitcoin SV (a fork of Bitcoin), but now providing more support to the native Bitcoin script (and with OP_CAT).
sCrypt is extremely powerful, as one can, for the first time, write complicated Bitcoin script without even the need to know opcodes. This has been used in the CAT20 protocol and has been used in production, which provides an improvement to Runes and Ordinals to significantly remove the centralization and scalability issues. Unisat wallet is also providing support for CAT20 protocol.
In general, a developer writes a function of the “Bitcoin smart contract” in TypeScript (with some handy builtin types and functions for Bitcoin). Then, it simply puts a modifier “@method()” to the function and makes some other changes. A compiler will compile this function into a method of the smart contract, much similar to the experience that Solidity is providing today.
A good example to show the potential of sCrypt is the transfer logic of CAT20. It is basically written in TypeScript, and an interested reader can just open this file to look at the script.
Think about token transfer. A token transfer takes N inputs and produces M outputs, each input has an owner and an amount, same for each output. To validate a token transfer, it is equivalent to validating:
Total In = Total Out
The CAT20 transfer script does the following. It first calculates the total amount of tokens from the input, with the TypeScript as follows.

The checking of `script == preState.tokenScript` is to make sure that the input is the valid CAT20 contract, and if so, its input token amount would be added to `sumInputToken`, which works as an accumulator. The final check `assert(sumInputToken > preSumInputToken)` is a sanity check.
The output follows a similar workflow, but additionally requires the output scriptSig to match the one of the CAT20 protocol. It similarly computes the sum of the output and checks other things about the outputs. Lastly, the script checks if the input and the output matches.

The rest of the contract is more generic covenant wrapper. One should, however, find that CAT20 has been implemented in this DSL—sCrypt—and it does not require a developer to learn Bitcoin script.
Compared with the DSL of sCrypt that targets more on covenants and smart contracts, our DSL focuses more on the computation, especially complicated computation that needs to be split, such as the Bitcoin STARK verifier. We have plans to integrate our DSL with sCrypt—so users in sCrypt can invoke the Bitcoin STARK verifier in TypeScript with a few lines of code one day.
What should a DSL for Bitcoin look like?
Our DSL is based on Rust and is an embedded domain-specific language (eDSL), meaning that it is more like a library in Rust that does not require a separate toolchain or IDE support. It is somewhat more than a library because our DSL introduces some new abstractions:
Bitcoin variables
Bitcoin functions
Bitcoin script generators
And some builtin functionalities such as memory for Bitcoin script and covenant.
To help understand why we want to create these abstractions, it is useful to highlight the challenges or “bad ergonomics” that developers have encountered when writing Bitcoin scripts, using the Fibonacci verifier that we built as an example.
First challenge: stack management. When Victor Kolobov from Starkware and I wrote the Fibonacci verifier back in June and July, it consumed a lot of brain power because we needed to keep track of the *relative* locations of the variables in the stack.

In the entire verifier implementation there are tens, if not a hundred, of code that look like this, in which we draw out the current stack in the comment with the different variables (such as “random_coeff2”) and their length (such as 4). To compute the prepared pair vanishing parameters, we need to retrieve “masked_points” and “oods_point” from the stack.
In Bitcoin, to retrieve elements from the stack, one needs to provide the *relative* distance between the element you are retrieving and the top of the stack (which would be at the bottom of the stack that we draw). This is very unfriendly because when an element is copied (to the top of the stack), the relative distance of the other elements to the stack top can change (some of them remain unchanged, some of them have larger distance). Then, when we run the prepared pair vanishing procedure for each of the 4 points (indicated by “prepare_pair_vanishing_with_hint”), it consumes 8 elements from the stack top and produces 4 elements to the stack top, this again changes the relative distances.
So, the distance “16 + 12 + 4 * i + (8 + 24) - 8 * i - 1” from the code is calculated as follows, starting from the top of the stack:
Skip the “(a, b), (a, b), (a, b), (a, b) for composition” which has 16 elements
Skip the “(a, b), (a, b), (a, b) for trace” which has 12 elements
Take into consideration the 4 elements produced as a result of prepared pair vanishing after one point
(8 + 24) - 8 * i - 1 brings us to the first element of the 8 elements of the corresponding point.
There are many problems with this way of writing scripts.
It takes a lot of mental effort to do such calculations, and one usually needs to keep track of the current stack layout (in our case, we write them down in the code as comments).
It is error-prone, and a bug can be fairly invisible. If a location is incorrect, the script will behave “weirdly” and it is hard to immediately realize that it is due to wrong stack locations.
A change in the previous step may impact the stack layout and require all the programs after it to update the formulas, making it difficult to manage large computation.
Such a manual way of maintaining the stack is also not optimal—for values that are no longer needed in the subsequent execution, they will remain in the stack unless we manually remove them. In addition, since the stack is copied during the entire execution from one program to another, it would waste stack space if unused variables are not timely removed.
This leads to the first requirement that we want from an DSL:
A Bitcoin DSL should be able to automate and optimize stack management.
Second challenge: carrying the state. We usually split the entire Bitcoin STARK verifier into several smaller transactions, which are easier to go through the Bitcoin network and have less impact on other pending Bitcoin transactions in the mempool. This, however, requires us to be able to pass the intermediate state from one transaction to another.
In the old Fibonacci verifier, we use a design called “StackHash”, which was originally from Carter Feldman from QED, that enables one to split a long computation into smaller transactions. The idea with “StackHash” is that it can save the current execution’s state by hashing it and putting in an UTXO on the Bitcoin chain, and later, in the next execution, it can retrieve that UTXO from the Bitcoin chain and extract the stack elements back.
By doing so, one can resume the same stack that was at the end of the previous execution, and continue the rest of the execution as if it is the same program, as illustrated below.
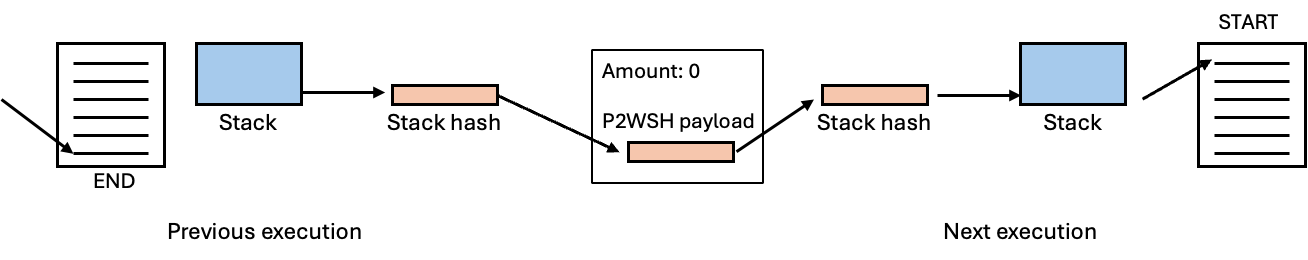
The main problem with “StackHash” is that it has a lot of redundancy, has a scalability problem, and is not flexible—it can and can only hash the entire stack.
When the stack is large, it would make the next execution more expensive because the next one needs to load the entire stack back.
The next execution may only need to access a few elements in the stack, but the entire stack is provided.
Between every two consecutive executions, one needs to make a decision on the layout of the final stack and make sure that the two executions agree with each other.
One needs to organize the stack so that values that are ready to be shared to the next execution stay in the stack until the end.
To use “StackHash”, we do two things: (1) at the beginning of an execution, unpack the stack hash into the full stack and (2) at the end of an execution, pack the stack into a stack hash. An example from the Fibonacci verifier is as follows.

Before the execution, it unpacks the stack given the length of the previous stack (which is the long formula shown above, corresponding to the stack layout in the comment from the bottom to the top). One can see that there are quite a lot of elements in the stack.
After the execution, the stack changes. For good practice, we again list the new stack layout in the comment and then we use “StackHash” to pack the stack, to be used for the next step.

Although “StackHash” does the work, it is a little bit tedious, and it does require the similar stack management overhead. Is there a way to carry the state in a more human-friendly way?
To answer this question, we should first jump out of Bitcoin and ask ourselves, what is the way that a regular programmer working in C++/Java/Rust would use to load and save a state? It can be a filesystem. It can be a config file. It can be a database. One of the reasons why these modern abstractions are extremely user-friendly is that they offer a key-value interface.
This leads to the second requirement that we want from an DSL:
A Bitcoin DSL should provide a modern state load/save interface.
Third challenge: high-level programming. If you think about the fact that the Fibonacci verifier is built by connecting together different Bitcoin scripts, written using the opcodes, you may start to worry about developer ecosystem, since most of the developers would have never used any Bitcoin opcode before, and they would not know anything about Bitcoin script.
This is more concerning because there is also a lack of learning materials for Bitcoin script—for example, although Udemy has around 1100 online courses talking about Solidity, there is only one actually talking about Bitcoin script that charges $119.99.
The actual problem about Bitcoin programmability is probably not about teaching people about Bitcoin script, but developing a high-level language. Writing in Bitcoin script is very similar to writing assembly in computer programming, or writing EVM bytecode in EVM. They are not going to be the way for mass adoption.

Throughout the history, we can see a consistent pattern about the evolution of programming languages—high-level languages that are more human-friendly and closer to other programming languages will gradually dominate, while the low-level languages like assembly or Bitcoin opcode will be used as the underlying building blocks of the high-level languages that developers do not need to know about, or be occasionally used for optimization or accessing low-level functionality.
What we want from a Bitcoin DSL is, therefore, making the language feel less-Bitcoin, but appear familiar to someone who knows another commonly used programming language.
This calls for third requirement that we want from a Bitcoin DSL:
A Bitcoin DSL also relieves developers from programming in Bitcoin script as much as possible.
Our DSL
We build an embedded DSL within Rust that meets the requirements mentioned above. First of all, we remove the need for the developers to manage the stack at all. Remember that previously, in order to perform prepared pair vanishing (a step in STARK proof verification) on a point, we have to calculate the distance between the point and the top of the stack, and the calculation becomes complicated when there are many elements in the stack already.
Solving the first challenge: stack management. The DSL now takes care of the stack management. In the script below written in our DSL, we have a point that is a Rust structure “SecureCirclePointVar”, we simply pass it over to the “prepare_pair_vanishing” function, to compute some parameters about the point.

There is no stack management that a developer needs to care about. The developer just needs to simply pass the variable “oods_point” as an input, as like in Rust.
The reason why this is possible is that the DSL assigns a number to each of the elements in the stack. You can think about “SecureCirclePointVar”, in addition to storing the x and y values, it also stores some unique numbers for its 8 elements on the stack. These numbers are fixed, in that they do not change when the stack grows or when some other variables are removed from the stack. The DSL will take care of the calculation of the relative position of these variables to the top of the stack.
How does our DSL do the distance calculation? It leverages a data structure called Fenwick tree.
The DSL assigns the numbers, starting from 0, 1, 2, …, to elements on the stack. If an element has a smaller number than another, then this element must be deeper down in the stack (or in other words, further away from the top of the stack). Elements may be removed (or, deallocated) from the stack if the DSL notices that they would not be used again—this poses a challenge because calculating the distance involves summing up the number of non-deallocated elements between this element and the top of the stack, while skipping all the elements that have been removed or deallocated. This implies a time complexity of O(N) because in the worst case we will need to check all the variables assigned already, where N is the number of elements ever allocated to the stack.
Fenwick tree is a data structure that reduces the time complexity to O(logN) and makes such calculation very affordable. This is because Fenwick stores a number of range sums. The distance to the top of the stack is a form of “partial sum”, and it can be computed by looking up only O(logN) range sums. When we allocate new elements into the stack, they are inserted into the Fenwick tree and the tree updates O(logN) range sums for each new element. When the DSL wants to deallocate a certain variable, it updates the O(logN) range sums accordingly. This allows the DSL to efficiently compute the distance between a variable to the top of the stack even if variables can be allocated and deallocated throughout the execution.
With this, the developer simply operates on the variables themselves in Rust, and the DSL will keep track of their locations in the stack and deallocate them when they are no longer in use.
Solving the second challenge: passing the state. Previously, we used “StackHash” to save the stack of the previous execution and load it at the beginning of the subsequent execution, and we mentioned that a desirable interface would be “key-value” because it is intuitive and human-friendly. Our DSL offers this interface.

In the example above, we want to compute the column line coefficients (which is an intermediate value for Bitcoin STARK verification). It needs to use the y coordinate of the out-of-domain-sampling (OODS) point (“oods_y”) and the evaluation on “mult”, “a_var”, “b_val”, “c_val” polynomials from previous executions. This is done by calling the “read” method of the LDM, using a human-friendly name for that variable.
The computation results will be saved to be used in a few future executions that use the column line coefficients. This is done by calling the “write” method of the LDM. These intermediate variables are used at a later time of the Bitcoin STARK verification, as follows, and all a developer needs to do is to provide the name of the coefficients here.

As the name suggests, the lightweight deterministic memory (LDM) is a carefully crafted memory implementation for Bitcoin that is, of course, lightweight. We will describe our construction of LDM in another technical article and talk about memory in Bitcoin script in general.
But in summary, LDM provides a key-value interface that basically solves the problem of carrying the state between small scripts that constitute a larger computation.
Solving the third challenge: high-level programming. As one can see from the previous examples, the coding has not yet involved any Bitcoin opcode. This is because many of these functions can directly call what we call standard library functions of our DSL (which are just Rust functions), and a developer does not have to write any Bitcoin script.
One such example is our implementation of out-of-domain-sampling (OODS), shown below, which is an important step in Bitcoin STARK verification. The computation it needs to perform is to:
Obtain a random element “t” from the builtin Fiat-Shamir transform.
Compute x = (1 - t^2) / (1 + t^2)
Compute y = 2t / (1 + t^2)\
The code in our DSL is as follows.

This does not involve any Bitcoin script. Rather, it simply performs the computation directly on the variable (here, “t”). This is much less error-prone and is easy to read—given all the human-friendly variable names.
There are still situations when we want to write some Bitcoin script. One situation is when the standard library does not have the required functionality, but more frequently for us is that we already have some code in Bitcoin script that has been tested before and we want to simply reuse the code.
One such example in our Bitcoin STARK verifier is “decompose_positions”, which, given a position on the Merkle trees, computes a few related locations for the STARK verification. Since this is very application-specific, it is understandable that the standard library does not have it.

In our DSL, one can use “insert_script” (or “insert_script_complex” for scripts with parameters) to insert the raw Bitcoin script. The inputs to the script (which would be placed at the top of the stack for the script) is provided as the second parameters (“variables”), and the DSL would take care of the stack management to prepare the inputs for the script.
Next steps
Our team’s focus is still on building the Bitcoin STARK verifier, and it seems that this goal is not very far away. We feel that the best way to develop a DSL is to use it—and when we find that there is redundancy or inconvenience in writing the STARK verifier with the DSL, we can come back to improve the DSL.
We will have more articles coming out that talk about Bitcoin STARK verifier and covenants, as well as its application, such as the CAT20 protocol (and we can explain why it is extremely similar to ERC20).
Acknowledgements
We want to thank Xiaohui Liu from sCrypt for providing advice about implementing a DSL. sCrypt offers a TypeScript-like DSL for writing Bitcoin scripts, which is useful, in particular, for writing covenants, and is being used to build a token bridge for StarkNet.
Bitcoin Signet contributors (we are still not sure who sent us the test tokens, maybe Satoshi?) and Fractal have sponsored the transaction fees for our prototype.
Find L2IV at l2iterative.com and on Twitter @l2iterative
Author: Weikeng Chen, Research Partner, L2IV
Disclaimer: This content is provided for informational purposes only and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisors as to those matters. References to any securities or digital assets are for illustrative purposes only and do not constitute an investment recommendation or offer to provide investment advisory services.